Видео с ютуба Ollama Mlx

Ollama перешла на Apple MLX — вот почему всё работает быстрее.

Ollama на базе MLX на M5 Max: 128 ГБ ОЗУ для невероятно высоких локальных уровней LLM! 🤯

Ollama vs MLX Inference Speed on Mac Mini M4 Pro 64GB

Ollama Mac MLX уже здесь — в 2 раза быстрее по скорости передачи данных для Apple Silicon Mac/Mac...

Ollama на Mac стала в 2 раза быстрее (вот как это сделать)

Мой M5 Max, Gemma 4, локальный стек MLX. (Это убивает поставщиков моделей)

Apple MLX vs llama.cpp: Which is Really Faster? (4 Runtimes - Ollama Included)
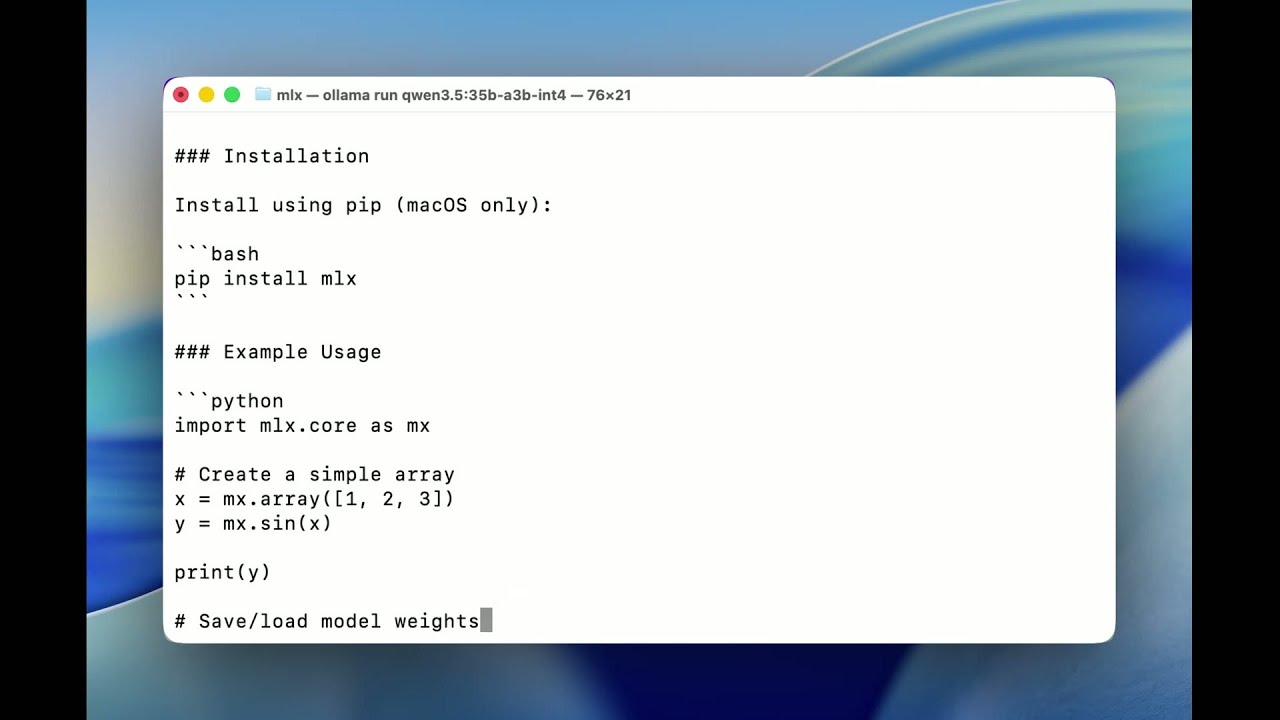
Ollama 0.19 MLX on Apple Silicon — 2x Faster, Fully Local

MacBook Pro M5 Max Local LLM Speed Test LM Studio vs Ollama vs MLX - Qwen3.5 - Llama 3.3 ローカルLLM検証

Разница в точности Qwen3-VL на Ollama и MLX

🗑️ Ollama 쓰레기통에 버리고 MLX로 갈아탄 이유 - 속도 미쳤다 " 맥북 유저 필수 시청 🚀

oMLX vs Ollama: Extreme Context, SSD KV Cache & Mac Crashes

FineTuning LLMs with MLX is Stupidly Easy

WWDC25: Explore large language models on Apple silicon with MLX | Apple
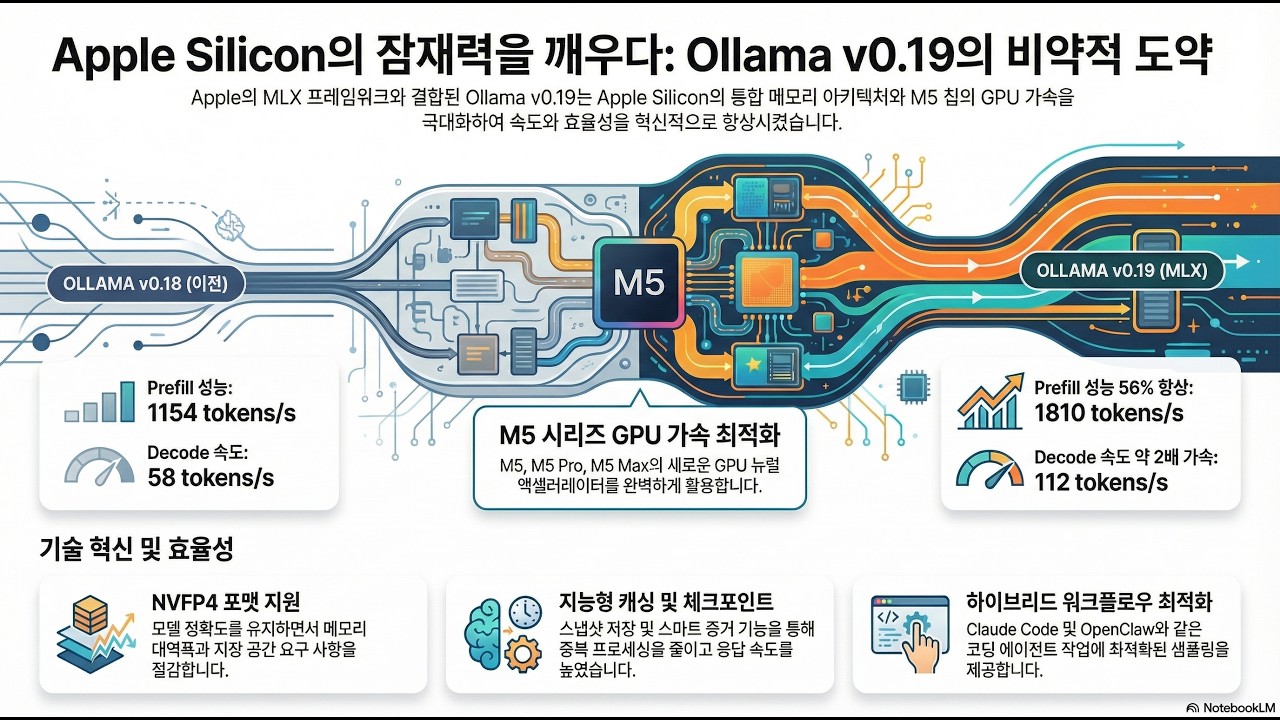
Ollama의 MLX 업그레이드
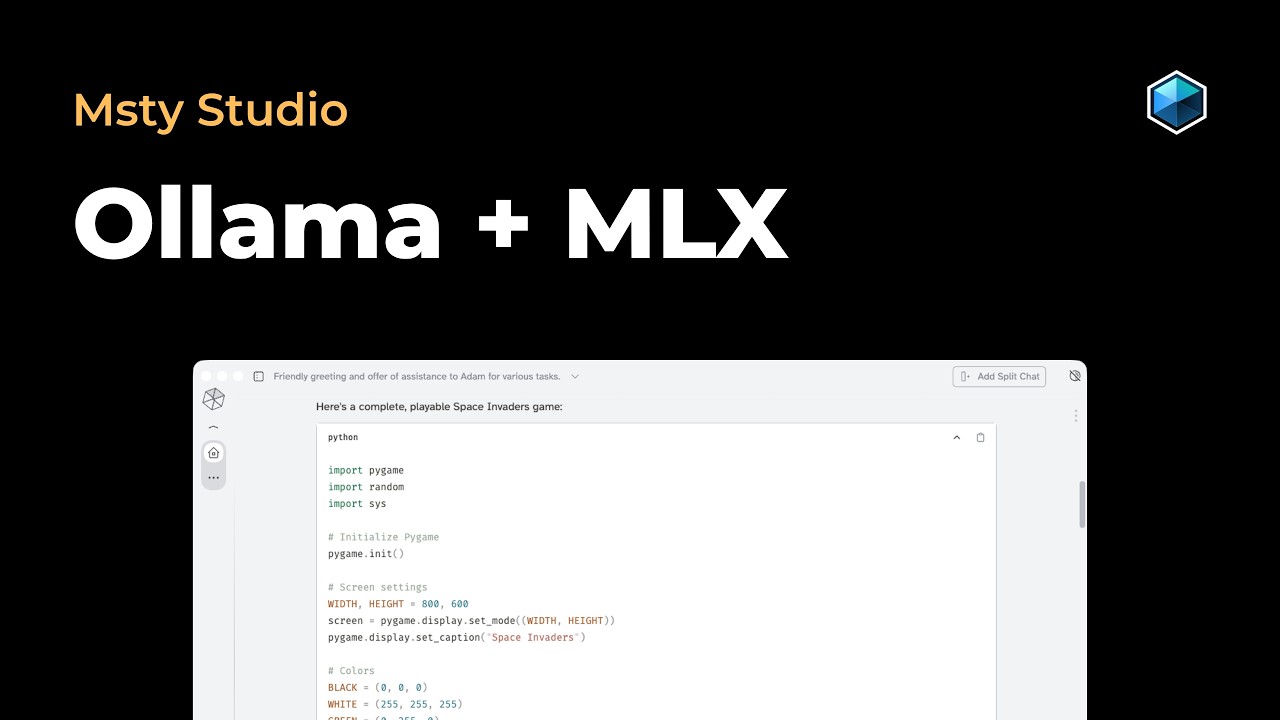
Попробуйте предварительную поддержку MLX в Ollama в Msty Studio.

Ollama が Apple Silicon で MLX をサポートし早くなったらしいので触ってみた